
As an admissions professional working within Slate, you know that data is crucial to your recruitment strategies. The more you know about prospective students and their behavior, the more effectively you can engage and enroll them. However, with the vast amount of data generated not only by applicants, but also by inquiries, even the most technical users among us can feel overwhelmed. That’s where Slate’s configurable joins feature comes in.
This powerful tool enables you to connect multiple data tables across your instance more seamlessly than what’s possible on local and Slate Template Library query bases. Unfortunately, the complexity of configurable joins has made it difficult for many Slate users to take full advantage of its capabilities.
In this blog post, we’ll guide you through some configurable joins terminology, and walk you through the single biggest obstacle we see when teaching new users about configurable joins. Don’t let this obstacle stand in the way of achieving your data goals!
Before we touch upon how to overcome this obstacle, it is important to provide some brief background on configurable joins. The first question you may be asking yourself is, “what even is a ‘join’, anyways, much less a ‘configurable’ one?”. That is an excellent first question.
A “join” simply refers to the act of joining two different data tables in Slate. For example, you may be starting a query from the base of “application”, which will generate one row of data per application. Here, the “base” of your query is simply which data table you are starting from.
You likely have plenty of data stored on your application tables within Slate, such as the round of the application, the date it was submitted, or the intended start term of the application. Within your query, you may bring in data associated with the “person” table of your instance, such as the name or email of the person submitting the application. Doing so would initiate a “join” to the person table in your instance.
The same concept is true of a configurable joins query you can create on a “person” base. This type of query would return you one row per person in your instance. You may decide to pull exports for the person’s name or email, much like you’ve done in the first query. However, you can use configurable joins here in the opposite direction to pull in data about any applications the student has on file. This data can include what we’ve mentioned before, like round or entry term.
The ability to “join” these disparate tables allows for querying of data from a number of different sources within Slate. This type of querying is not limited to just persons and applications within your instance, but instead encompasses any object in the instance, from school, to sport, to user, to form.
However, how you join these tables is critically important. This is the “configurable” part of configurable joins, and often where users may stumble.
If you simply add in a table join to the bottom of your query that may have a one-to-many relationship, like applications, you will have to specify which application you are interested in examining. There is just one person record in Slate, but that person might have many applications.
Simply put, if you click this button from a person-based query:
And if you then join to the application table, you’ll notice this:
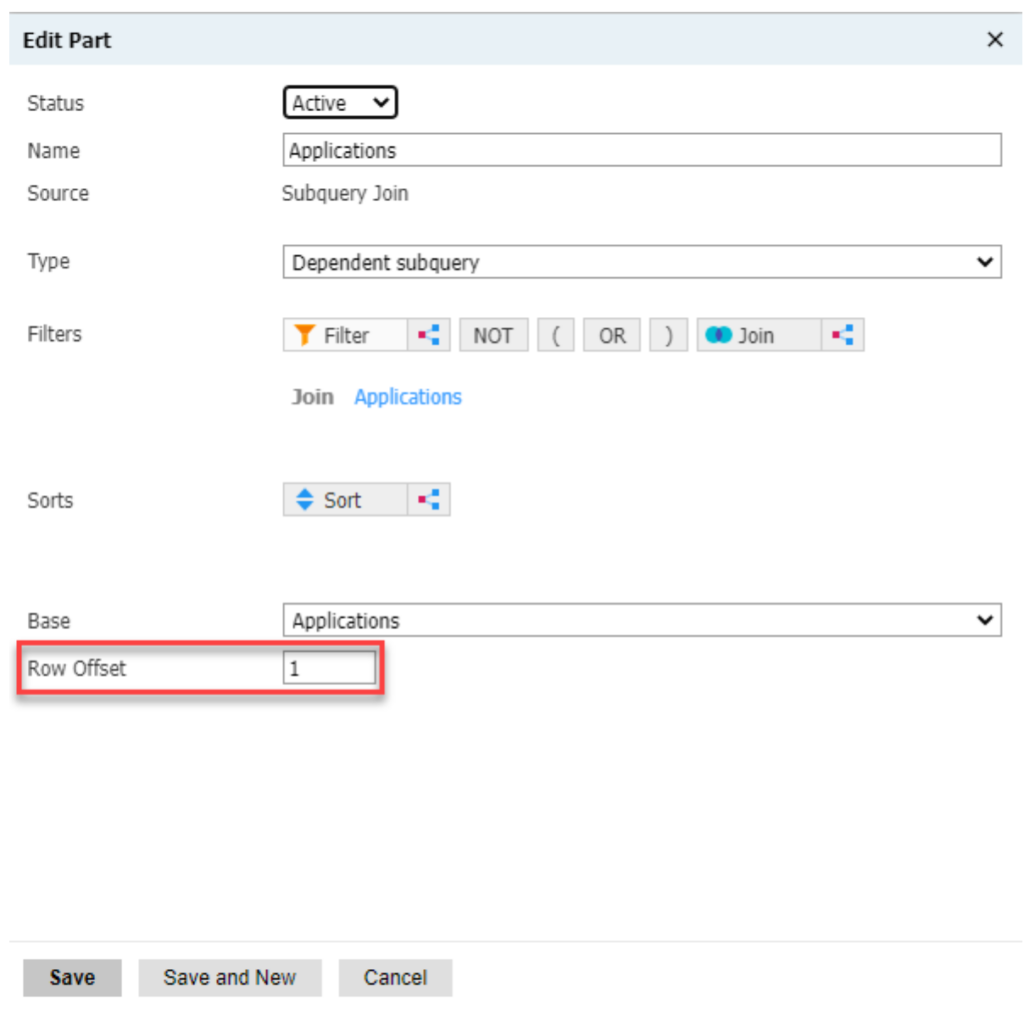
This row offset line indicates that Slate will only be looking at the first application table on the student’s record. You can add additional sort criteria to specify what that first application should be for Slate, but if you want to examine all of the person’s applications on file, this approach will not work.
A better bet might be to bring in what Slate would call a “subquery export”
From here, you’ll notice within this export you can still join to the application, but in this case, you are joining to all of the applications on the person record. In this one-to-many relationship, you are now able to examine the many applications that might be on file for a person.
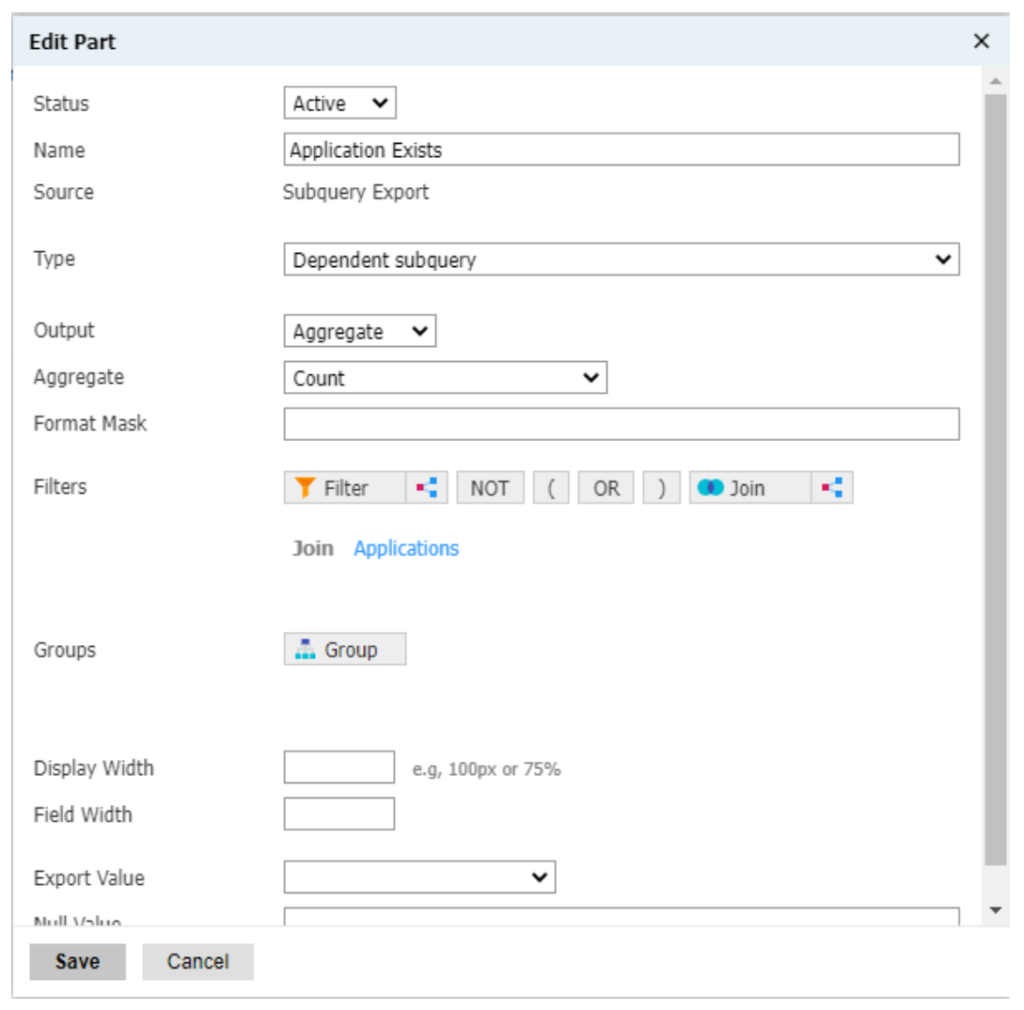
And here, you’ll have much more flexibility regarding the exports you can create. For instance, you can check to see if the person has any application record on file:
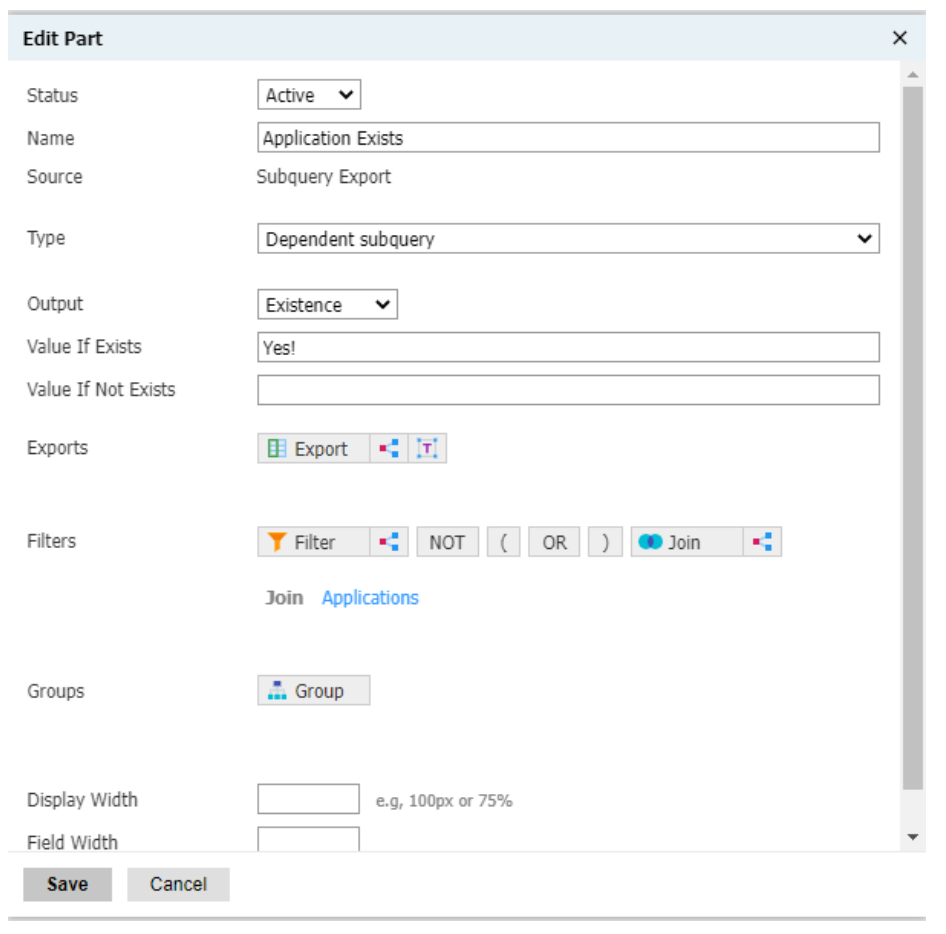
You can count the number of applications the student has submitted:
You can even begin to put together more advanced exports. For example, should you want to export the round names for all of the submitted applications a person submitted, separated by a comma, you would be able to do so by mirroring the below:
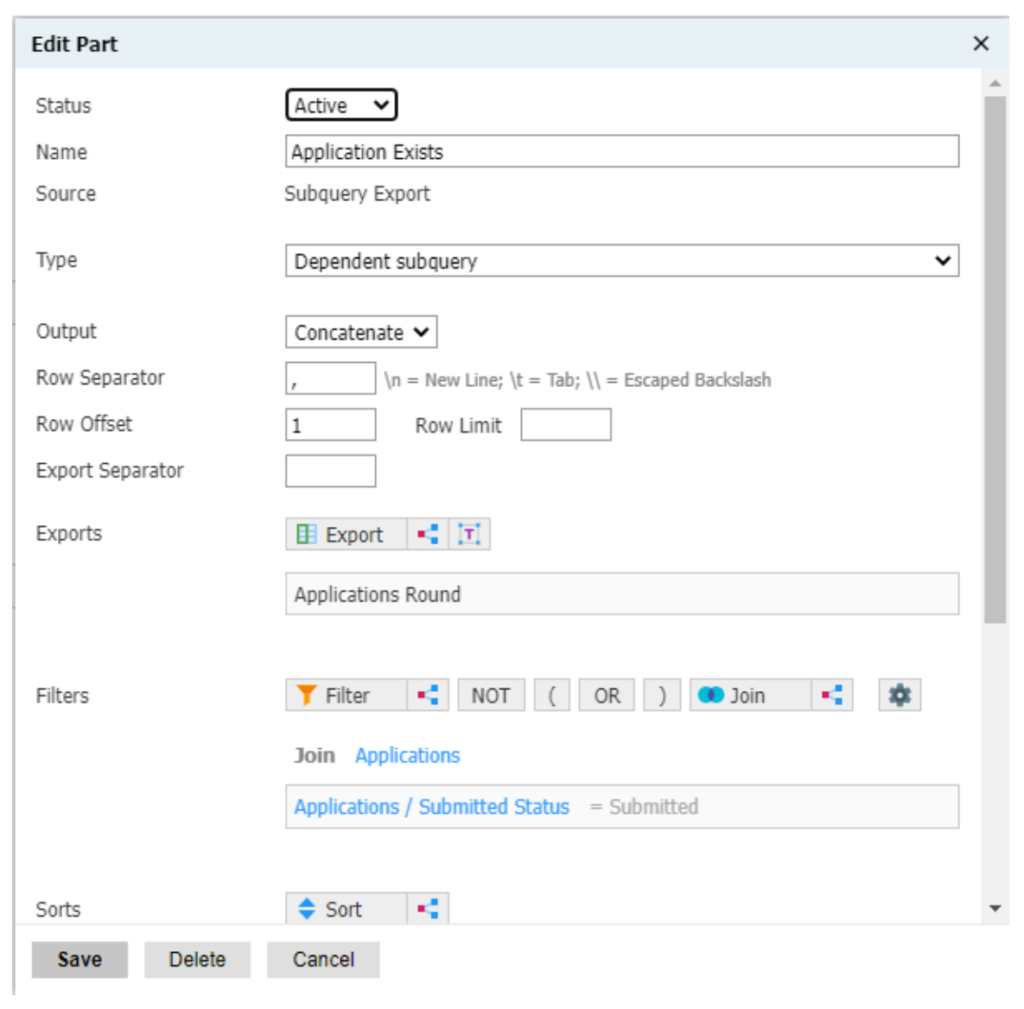
In summary, any joins added to the bottom of the query will only allow you to join to one data table, while joins contained within a subquery export allow you to examine all data tables in a one-to-many relationship
Once you’ve grasped the concept of where exactly you should place your join, you can begin to unlock the power configurable joins has to answer your toughest data questions, and to streamline your admission processes. If you can keep this in mind, you are on your way to becoming a configurable joins pro!
And of course, if you’re just starting out in your instance, or if you’re a seasoned Slate professional looking for advanced configurable joins guidance around Ping, your portal, your rules editor, or anything else in your instance, don’t hesitate to reach out. Our team of Slate experts is ready to help you.